超融合服务器工作逻辑深度解析
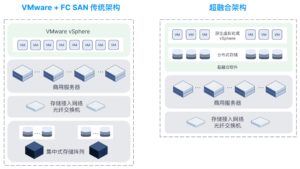
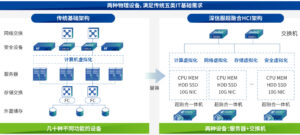
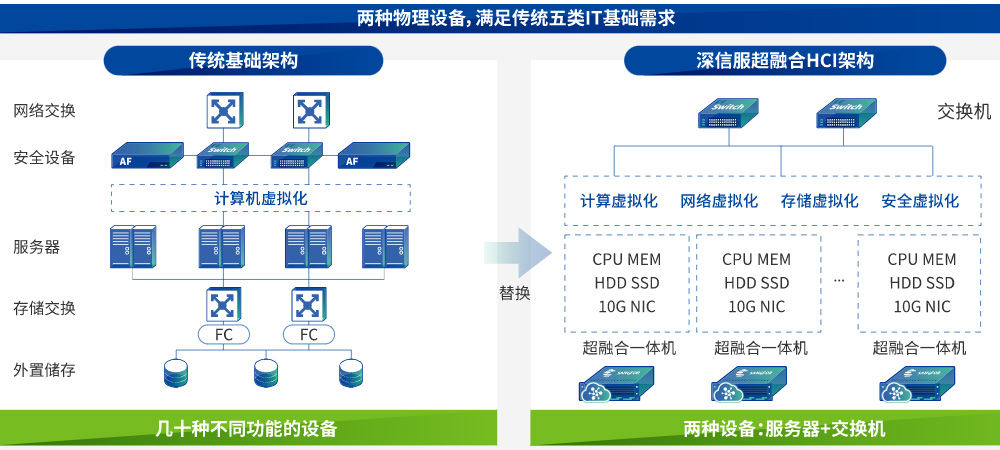
在传统IT架构中,服务器、存储、网络采用相互独立的“烟囱式”部署模式——计算资源由物理服务器提供,存储依托专用SAN/NAS设备,网络则需单独配置交换机与路由策略。该架构存在资源利用率低下、扩展成本高昂、运维复杂度高的显著问题。而超融合基础设施(Hyper-Converged Infrastructure,HCI)的出现,通过“软件定义”打破硬件边界,将计算、存储、网络功能整合至标准化服务器,打造出弹性可扩展的IT基础设施。本文将从底层架构拆解、核心技术原理、组件协同机制三个维度,深入解析超融合服务器的工作逻辑。
一、超融合服务器的底层架构
超融合服务器的核心特征为“硬件通用化 + 软件定义化”,其底层架构分为“物理硬件层”与“软件抽象层”两层,二者通过标准化接口实现解耦,为上层资源池化奠定基础。

1. 物理硬件层:标准化硬件集群是基础载体
与传统专用设备不同,超融合服务器的硬件采用x86架构标准化服务器,无需定制化硬件,仅需满足“计算 + 存储”一体化部署的基础配置要求:
- 计算单元:配备多颗多核CPU(如Intel Xeon、AMD EPYC),支持Intel VT-x、AMD-V等虚拟化扩展指令集,为虚拟机(VM)或容器提供硬件级计算隔离;
- 存储单元:每台服务器本地配置“SSD+HDD”混合磁盘组——SSD作为缓存层(Cache Tier),实现热点数据读写加速;HDD作为容量层(Capacity Tier),用于冷数据存储,通过分层存储提升IO效率;高性能场景可采用全SSD配置;
- 网络单元:每台服务器配备多块10GbE/25GbE网卡,一方面支撑节点间数据同步,构建分布式存储网络,另一方面承载业务网络流量,通过VLAN或VXLAN实现网络隔离;
- 冗余设计:硬件层面支持RAID磁盘冗余、多网卡绑定、电源/风扇冗余,有效避免单点故障引发的集群中断问题。
上述标准化服务器通过网络组成集群,每台服务器兼具“计算节点”与“存储节点”属性,彻底消除了传统架构中存在的“集中式存储瓶颈”。
2. 软件抽象层:打破硬件边界的核心引擎
软件抽象层是超融合架构的核心,其核心作用是将集群内分散的CPU、内存、磁盘、网卡等硬件资源抽象为统一的“资源池”,并通过软件定义的方式实现资源按需分配。该层包含三大核心组件:
- 虚拟化引擎:负责计算资源的抽象与调度,主流产品包括VMware ESXi、开源的KVM、Hyper-V等;
- 分布式存储引擎:负责存储资源的池化与管理,是超融合架构与传统架构的核心差异点,主流产品有Ceph、开源的GlusterFS、VMware vSAN(商业)等;
- 软件定义网络(SDN)引擎:负责网络资源的虚拟化与控制,如Open vSwitch(OVS)、VMware NSX,可实现网络策略的自动化配置。
三大组件并非独立运行,而是通过VMware vCenter、深信服HCI管理平台等统一管理平台协同工作,形成“计算-存储-网络”一体化的资源调度体系。
传统架构与超融合架构对比(层级结构表)
| 架构类型 | 硬件组成 | 资源连接方式 | 核心痛点 / 优势 | 典型延迟(IO 路径) |
|---|---|---|---|---|
| 传统架构 | 1. 计算:独立物理服务器集群<br>2. 存储:集中式SAN/NAS设备<br>3. 网络:专用光纤交换机 + 路由器 | 1. 服务器→光纤交换机→SAN<br>2. 服务器→物理交换机→路由器(多设备串联) | 痛点:<br>1. 资源利用率<20%<br>2. 扩展需采购专用设备<br>3. IO路径长(6-8跳) | 5-10ms |
| 超融合架构 | 1. 计算:x86标准化服务器(每节点含CPU/内存)<br>2. 存储:每节点本地SSD+HDD<br>3. 网络:每节点10GbE/25GbE网卡 | 1. 节点间通过标准以太网直连<br>2. 计算/存储/网络集成于单节点(扁平化连接) | 优势:<br>1. 资源利用率>60%<br>2. 扩展仅需添加服务器<br>3. IO路径短(2-3跳) | 1-3ms |
关键差异:传统架构呈现“三层分离”的垂直结构,超融合架构呈现“节点集成”的水平结构。
二、核心技术原理:三大引擎如何实现“资源池化”与“弹性扩展”
超融合架构的底层能力,本质是三大核心引擎通过特定技术机制,解决“分散资源如何协同”“数据如何安全存储”“资源如何按需调度”三大核心问题。
1. 虚拟化引擎:计算资源的“切片”与“隔离”
虚拟化引擎的核心是硬件辅助虚拟化技术,其原理是在物理CPU与操作系统之间增设一层“虚拟机监控器(Hypervisor)”,将物理CPU的计算能力“切片”为多个虚拟CPU(vCPU),并为每个VM分配独立的内存、IO资源,实现“一台物理机运行多台虚拟机”的隔离部署。
以主流的KVM为例,其底层工作机制如下:
- CPU虚拟化:依托Intel VT-x/AMD-V指令集,Hypervisor可直接调用硬件虚拟化能力,规避传统“全虚拟化”的性能损耗,使vCPU的运算效率接近物理CPU(性能损耗通常低于5%);
- 内存虚拟化:通过Intel EPT、AMD NPT等“内存地址转换”技术,将VM的虚拟内存地址映射到物理内存地址,同时支持“内存超分配”(如物理内存128GB,可分配给VM的总内存达256GB),并通过LRU等内存页置换算法动态调整,提升内存利用率;
- IO虚拟化:通过“半虚拟化IO(virtio)”技术,在VM与物理IO设备(网卡、磁盘)之间搭建高效通信通道,突破传统“模拟IO”的性能瓶颈——例如,virtio-net网卡的吞吐量可达物理网卡的90%以上,远高于e1000等模拟网卡。
此外,虚拟化引擎支持“动态资源调度(DRS)”——当某台物理机CPU利用率过高时,管理平台会自动将VM迁移至负载较低的节点,实现计算资源的均衡分配。
2. 分布式存储引擎:存储资源的“池化”与“高可用”
分布式存储是超融合架构的核心差异化技术,其原理是将集群中所有节点的本地磁盘(SSD+HDD)整合为统一的“分布式存储池”,通过“副本机制”或“纠删码”实现数据高可用,同时借助“分布式哈希表(DHT)”实现数据的高效定位与读写。
以开源分布式存储Ceph为例,其底层工作流程可拆解为三步:
- 数据分片与定位:当VM写入数据时,Ceph客户端将数据切分为4MB-64MB的“对象(Object)”,并通过CRUSH算法(基于哈希的分布式调度算法)计算每个对象的存储节点——该算法会综合考虑节点负载、磁盘容量、网络拓扑,确保数据均匀分布在不同节点,避免单点依赖;
- 数据冗余与存储:为保障数据不丢失,Ceph将每个对象复制为多个副本(通常为3副本),存储在不同节点的磁盘上——例如,对象A存储在节点1的SSD、节点2的HDD、节点3的SSD,即便节点2故障,仍可从节点1和3读取数据;部分场景可采用纠删码(如EC 4+2,即4份数据+2份校验码),在保障高可用的同时降低存储开销(相比3副本,存储利用率提升25%);
- 数据读写加速:Ceph通过“缓存分层”优化IO性能——热点数据(如频繁读写的数据库文件)优先存储在SSD缓存层,冷数据自动下沉至HDD容量层;同时支持“读缓存命中”与“写缓存聚合”:读操作优先从本地缓存读取,未命中时再从其他节点拉取;写操作先写入本地缓存,再异步同步至其他副本,降低写延迟。
分布式存储Ceph IO流程
流程总览:数据从虚拟机到存储节点的5步映射
虚拟机文件 → 切分Object → 映射至PG → 分配OSD节点 → 多副本存储
详细步骤拆解(含关键技术点)
| 步骤 | 操作主体 | 核心动作 | 技术支撑 | 结果 / 作用 |
|---|---|---|---|---|
| 1 | 虚拟机客户端 | 将文件按4MB-64MB切分为Object,生成唯一标识oid(如obj-123) | 数据分片算法 | 避免单文件过大导致的读写效率降低 |
| 2 | 客户端 | 计算Hash (oid) & 掩码 → 得到PG编号(如pg-45) | 一致性哈希 | 将多个Object归类到不同PG,便于统一管理 |
| 3 | 客户端 | 调用CRUSH算法,输入pg-45 + 集群拓扑 → 输出主OSD + 副本OSD(如OSD1为主,OSD2/3为副本) | CRUSH分布式调度算法 | 确保数据均匀分布在不同节点,无单点依赖 |
| 4 | 主OSD1 | 接收客户端写入请求,同步数据至OSD2/OSD3 | 主从副本同步机制 | 实现3副本冗余,可容忍2个节点故障 |
| 5 | 主OSD1 | 收到OSD2/OSD3写入成功响应后,向客户端返回“写入完成” | 确认机制(ACK) | 保障数据不丢失,满足金融级可靠性要求 |
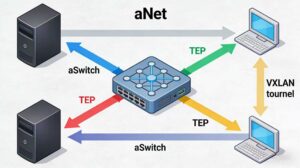
3. 软件定义网络(SDN):网络资源的“虚拟化”与“自动化”
传统架构中,网络配置依赖人工操作(如VLAN划分、路由配置),难以适配超融合集群中VM动态迁移的需求。SDN的核心是“控制平面与数据平面分离”——通过OpenDaylight等集中式控制器管理网络策略,再借助OVS等虚拟化交换机实现数据转发,解决“网络跟随VM迁移”的问题。
其底层关键技术包括:
- 虚拟交换机(OVS):部署在每台超融合节点上,负责VM之间、VM与物理网络之间的数据转发。OVS支持“流表规则”——控制器通过下发流表定义VM的通信策略(如允许VM1访问VM2、禁止VM3访问外网),无需人工配置物理交换机;
- VXLAN隧道技术:当VM在不同物理节点间迁移时,传统VLAN(仅支持4096个网段)无法满足跨节点网络隔离需求。VXLAN通过在IP数据包外层封装UDP隧道(VXLAN头),将VM的虚拟网络(VNI,支持1600万个网段)映射到物理IP网络,实现跨节点的VM二层通信——例如,VM1从节点A迁移到节点B后,其IP地址和MAC地址保持不变,VXLAN隧道会自动将数据包转发至新节点,业务无感知;
- 网络策略自动化:SDN控制器可与超融合管理平台联动,创建VM时,控制器自动下发对应的网络策略(如IP地址分配、安全组规则);VM迁移时,网络策略同步跟随,避免人工配置失误。
4. 模块关系:架构分层(从上到下)
应用层
- 包含:虚拟机/容器、数据库/VDI/虚拟化桌面等业务系统
- 依赖:向虚拟化引擎申请计算资源,无需关注底层硬件具体配置
软件抽象层(核心协同层)
| 引擎类型 | 核心功能 | 与其他引擎的协同关系 | 硬件依赖 |
|---|---|---|---|
| 虚拟化引擎(KVM/ESXi) | 1. 抽象CPU/内存为vCPU/虚拟内存<br>2. 管理虚拟机全生命周期 | 1. 向分布式存储引擎申请虚拟磁盘<br>2. 向SDN引擎申请网络配置 | 依赖CPU的VT-x/AMD-V指令集 |
| 分布式存储引擎(Ceph) | 1. 池化所有节点的SSD/HDD<br>2. 提供块/对象存储服务 | 1. 接收虚拟化引擎的IO请求<br>2. 通过SDN引擎实现跨节点数据同步 | 依赖SSD的随机读写性能 |
| SDN引擎(OVS+VXLAN) | 1. 虚拟交换机转发流量<br>2. VXLAN实现跨节点网络隔离 | 1. 为虚拟化引擎的虚拟机分配IP/安全组<br>2. 为存储引擎提供高带宽数据通道 | 依赖10GbE以上规格网卡 |
| 统一管理平台 | 1. 实时监控三大引擎运行状态<br>2. 一键调度各类硬件资源 | 连接所有引擎,统一下发配置指令 | 无硬件依赖,可部署于集群任意节点 |
物理硬件层
- 标准化x86服务器:每节点配备多核CPU、SSD+HDD混合存储、高速网卡
- 节点间通过以太网互联互通,形成集群(支持2-200+节点弹性扩展)
三、组件协同机制:从“单一节点”到“集群整体”的资源调度逻辑
超融合服务器的底层能力并非依赖单一组件,而是通过“计算-存储-网络”的深度协同,实现资源的动态调度与故障自愈。本文以“VM创建与迁移”典型场景为例,解析其协同流程:
- 资源申请与分配:管理员通过统一管理平台创建VM,明确指定CPU(2vCPU)、内存(8GB)、存储(100GB)、网络(VLAN 10)等资源需求;
- 计算资源调度:虚拟化引擎(如KVM)扫描集群所有节点负载状态,选定CPU利用率低于30%、内存剩余大于10GB的节点(如节点A),在该节点创建VM并分配对应的vCPU与内存资源;
- 存储资源调度:分布式存储引擎(如Ceph)根据CRUSH算法,在集群中选取3个节点(如节点A、B、C)的磁盘,为VM分配100GB存储空间,并创建3个数据副本;同时将VM的系统盘数据优先存储在节点A的SSD缓存层,提升VM启动速度;
- 网络资源配置:SDN控制器(如OpenDaylight)向节点A的OVS下发流表规则,为VM分配固定IP地址(如[192.168.10.10](192.168.10.10)),并绑定VLAN 10,配置外网访问权限;
- 动态迁移与自愈:当节点A的CPU利用率升至80%时,管理平台自动触发DRS,将VM迁移至节点D:
- 计算层:通过VMware vMotion、KVM Live Migration等“在线迁移”技术,将VM的内存数据实时复制到节点D,切换过程中断时间低于50ms;
- 存储层:因数据已通过副本机制存储在节点B、C,VM迁移至节点D后,可直接从B、C节点读取数据,无需重新拷贝;
- 网络层:SDN控制器自动更新OVS流表,将VM的网络流量转发至节点D,VM的IP地址与网络策略保持不变,业务无中断;
- 故障自愈:若节点B发生故障,分布式存储引擎会自动在其他健康节点(如节点E)上重建数据副本,恢复3副本冗余机制;同时,虚拟化引擎将依赖节点B存储的VM调度至其他节点,避免业务中断。
虚拟机动态迁移流程详解
迁移触发条件:源节点CPU利用率>80%(管理平台实时监控节点负载)
时序步骤(按时间顺序)
| 时间点 | 执行主体 | 动作描述 | 技术细节 | 业务影响 |
|---|---|---|---|---|
| T0 | 管理平台 | 检测到源节点A负载过高,触发DRS(动态资源调度),筛选出目标节点B(CPU利用率<30%) | 基于CPU/内存/存储负载的智能调度算法 | 无任何影响 |
| T1-T5 | 源节点A KVM | 将虚拟机内存数据预复制至目标节点B,仅复制脏页(已修改的内存页) | Live Migration技术,增量式数据复制 | 无任何影响,业务正常运行 |
| T6 | 管理平台 | 通知Ceph存储客户端:虚拟机将迁移至节点B,无需拷贝数据(数据已存储在B/C/D节点副本) | 多副本机制,实现存储与计算解耦 | 无任何影响 |
| T7 | SDN引擎 | 向目标节点B的OVS下发流表,配置VXLAN隧道,绑定虚拟机原有IP(如[192.168.10.10](192.168.10.10)) | VXLAN网络隔离技术,保障IP地址不变 | 无任何影响 |
| T8 | 源节点A KVM | 同步最后一批增量内存数据,将虚拟机运行节点切换至B,切换中断时间<50ms | 内存锁定技术,最小化业务切换窗口 | 业务无感知(如视频会议、在线业务无卡顿) |
| T9 | SDN引擎 | 将原节点A的虚拟机网络流量切换至节点B,关闭源节点A的虚拟机网络配置 | 流量平滑切换技术,无丢包、无延迟 | 无任何影响 |
| T10 | 管理平台 | 实时监控目标节点B的虚拟机运行状态(CPU/内存/IO),确认迁移操作成功 | 节点健康实时检查,异常情况自动告警 | 迁移完成,集群负载均衡机制生效 |
四、总结
超融合服务器的底层工作原理,本质是通过“软件定义”重构IT基础设施——以标准化硬件降低部署与采购成本,以虚拟化引擎实现计算资源的隔离与高效利用,以分布式存储打破传统集中式存储的性能瓶颈,以SDN实现网络配置的自动化与灵活性,最终构建出“弹性扩展、按需分配、故障自愈”的现代化IT架构。
其核心价值主要体现在三个方面:
- 资源利用率大幅提升:计算资源利用率从传统架构的20%提升至60%以上,存储容量浪费降低至10%以内;
- 扩展成本显著降低:新增集群节点仅需添加标准化x86服务器,无需采购专用存储/网络设备,整体扩展成本降低40%以上;
- 运维效率全面提升:通过统一管理平台实现“计算-存储-网络”一体化运维,大幅减少人工操作,运维工作量减少60%以上。